Waldo
Object Detection in Overhead
Imagery / Real Live Feed
WALDO / YOLO
Introduction
WALDO 3.0 (Whereabouts Ascertainment for Low-lying Detectable Objects) is an open-source artificial intelligence model designed for object detection in overhead imagery. Built upon the YOLOv8 (You Only Look Once, General object detection tool) architecture, WALDO 3.0 leverages synthetic data and “augmented” / semi-synthetic data pipelines to enhance its object recognition capabilities. It is a powerful tool for analyzing aerial imagery from drones, satellites and other overhead sources. The model can detect classes of items in overhead imagery ranging in altitude from about 30 feet to satellite imagery.
Background and Development
The development of WALDO 3.0 was driven by the need for an efficient, high-precision model capable of identifying various objects in aerial images. Traditional object detection methods struggle with variations in scale, lighting, and occlusion, which are common challenges in overhead imagery. WALDO 3.0 addresses these issues by using:
- YOLOv8-based architecture: A deep learning model optimized for real-time object detection.
- Synthetic data training: Enables robust performance across diverse environments and lighting conditions.
- Extensive dataset augmentation: Improves generalization for different geographic regions and contexts.
Key Features
WALDO 3.0 supports the detection of 12 distinct object classes:
- LightVehicle: Civilian cars, including pickup trucks and vans.
- Person: Individuals, including those on bicycles or swimming.
- Building: Various types of structures.
- UPole: Utility poles and similar vertical structures.
- Boat: Watercraft such as boats, ships, canoes, and surfboards.
- Bike: Two-wheeled vehicles, including bicycles and motorbikes.
- Container: Shipping containers, even when mounted on trucks.
- Truck: Large commercial vehicles, including articulated trucks.
- Gastank: Cylindrical tanks like butane tanks and grain silos.
- Digger: Construction vehicles, including tractors.
- Solarpanels: Solar energy panels.
- Bus: Public transportation buses.
Applications
Able to accurately detect various objects in overhead imagery, WALDO 3.0 has applications in multiple fields:
- Disaster Recovery: Assists in identifying affected areas and coordinating relief efforts.
- Wildlife Monitoring: Detects unauthorized intrusions in protected areas and tracks wildlife movement.
- Infrastructure Monitoring: Helps oversee construction sites and monitor the health of infrastructure.
- Traffic Flow Management: Analyzes vehicle movement patterns to optimize traffic systems.
- Occupancy Calculation: Assesses parking lot usage and crowd densities.
- Crowd Counting: Estimates the number of people in public spaces for event management and safety.
- Construction Site Monitoring: Tracks progress, detects anomalies, and ensures worker safety at construction sites.
- Drone Navigation and Safety: Enhances UAV navigation by identifying obstacles, no-fly zones, and ensuring avoidance of people and vehicles on the ground.
Performance and Limitations
WALDO 3.0 achieves high accuracy in detecting objects, particularly for well-represented classes such as LightVehicle and Person. However, its performance may vary based on:
Image Resolution
Higher resolutions yield better accuracy.
Object Size and Occlusion
Small or partially hidden objects may be more challenging to detect.
Environmental Conditions
Extreme weather or poor lighting can impact detection efficiency.
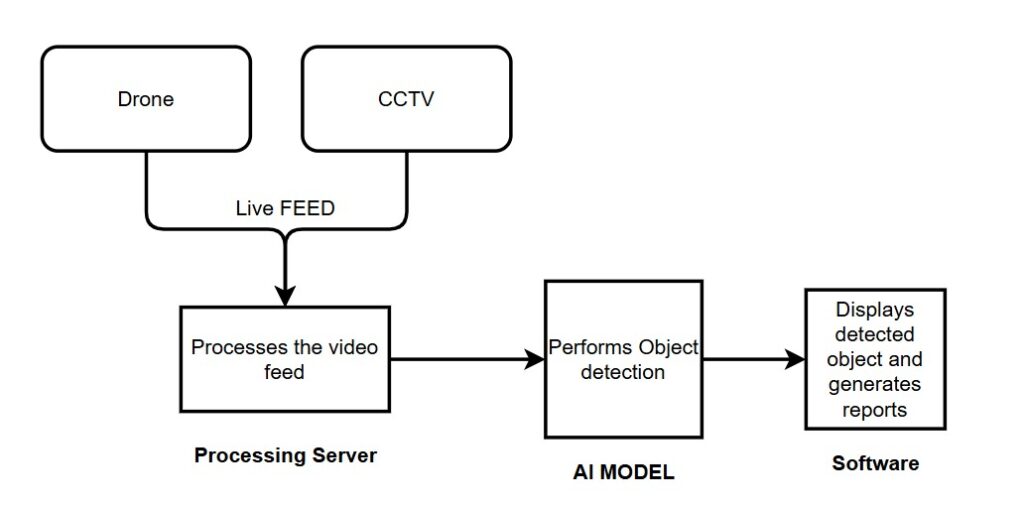
Research and Implementation
This implementation focuses to connect with a live camera feed, either from a drone or a CCTV system, to detect objects in a specific area.
Technology Choice
Initially, we considered using Waldo 3.0 for object detection. Since Waldo 3.0 also relies on YOLO (You Only Look Once), we opted to use YOLOv11 directly for object detection due to its robustness and extensive community support.
First Iteration: Testing with MP4 Videos
For the initial testing phase, instead of using live feeds, we used MP4 video files to inspect and evaluate the results of the object detection tools. This approach allowed us to validate the performance of YOLO before integrating it with real-time camera streams.
First Iteration: Testing with MP4 Videos
For the initial testing phase, MP4 video files were utilized to inspect and evaluate the results of the object detection. This approach allowed us to validate the performance of YOLO before integrating it with real-time camera streams.
Input
A variety of MP4 videos with different resolutions and pixel sizes to evaluate YOLO’s performance across various video qualities. Additionally, some of the videos are converted to a uniform resolution of 640×640 pixels to assess how YOLO performs when the input size is standardized.
Output
The output successfully detects multiple objects and tracks them across frames. However, due to video format inconsistencies, YOLO occasionally hallucinates objects—detecting items that aren’t actually present. Pre-processing the video, such as normalizing resolution, adjusting brightness/contrast, and stabilizing frames, can significantly enhance YOLO’s performance, reducing false detections and improving tracking accuracy.
Input Sample 1
Output Sample 1
Input Sample 2
Output Sample 2
Input Sample 3
Output Sample 3
Input Sample 4
Output Sample 4
YOLO: You Only Look Once (GitHub)
Overview
YOLO is a state-of-the-art, real-time object detection system that offers high accuracy and speed. Unlike traditional object detection techniques that rely on region proposal networks (R-CNN, Fast R-CNN), YOLO frames the detection problem as a single regression problem. It predicts bounding boxes and class probabilities directly from an image in a single evaluation.
Key Features of YOLO
- Real-Time Processing: YOLO can process images at high speeds, making it ideal for live feeds.
- End-to-End Training: Unlike other object detection models that use separate region proposals, YOLO is trained end-to-end, making it efficient.
- Global Context Awareness: YOLO looks at the entire image while making predictions, reducing false positives.
- Multiple Object Detection: It detects multiple objects in a single pass through the network.
- Anchor Boxes: YOLO uses predefined anchor boxes to help improve detection accuracy.
How YOLO Works
- Image Input: The input image is divided into a grid (e.g., 13×13 for YOLOv3).
- Bounding Box Prediction: Each grid cell predicts bounding boxes for objects that fall within it.
- Class Probability Prediction: Each bounding box is assigned a probability score for different object classes.
- Non-Maximum Suppression (NMS): The model applies NMS to filter out overlapping and low-confidence detections.
- Final Output: The final set of bounding boxes and object labels are produced.
Pre-Processing for Improved Detection
For YOLO to accurately detect objects, preprocessing will be performed as follows:
- Resizing Video to 640×640 Pixels: Converting the video frames to 640×640 pixels improves object detection by ensuring the input matches YOLO’s expected format.
https://docs.ultralytics.com/guides/preprocessing_annotated_data/#data-preprocessing-techniques
- Limiting Frames Per Second (FPS): Reducing FPS ensures that YOLO processes frames efficiently, balancing speed and accuracy for real-time applications.
https://docs.ultralytics.com/models/yolov7/
Improving Accuracy with Video Resizing
Resizing the video to 640×640 can improve YOLO’s object detection performance by ensuring the model receives inputs in the expected format. However, resizing must be done correctly to avoid loss of details or distortion.
Why Resize to 640×640?
- Matches YOLO’s Input Size: If the model was trained on 640×640 images, resizing ensures better accuracy.
- Preserves Aspect Ratio & Details: Avoids stretching or compression that can distort objects.
- Reduces Computational Load: Faster inference, especially for real-time applications.
Example of YOLO Object Detection Output
Below is an example of YOLO detecting objects in a traffic scene. The left side shows the processed frame with detected objects labeled, while the right side displays the original frame.

Next Steps
- Fine-Tune YOLO Model
- Train on a custom dataset for our use case if necessary.
- Adjust confidence thresholds to minimize false positives.
- Use data augmentation (rotation, brightness adjustments) to improve robustness.
- Optimize Video Processing
- Experiment with different FPS limits to balance detection accuracy and performance.
- Implement multi-threading to process frames efficiently.
- Implement Post-Processing Enhancements
- Use tracking algorithms (e.g., SORT, DeepSORT) to track objects across frames.
- Apply Non-Maximum Suppression (NMS) tuning to reduce duplicate detections.
YOLOv11 integration for real-time object detection using live camera feeds from drones or CCTV systems. Initially, MP4 videos were used for testing, revealing that while YOLO accurately detects and tracks multiple objects, video format inconsistencies sometimes cause hallucinated detections. Pre-processing techniques such as resolution normalization, FPS adjustment, and frame stabilization can significantly enhance accuracy. By fine-tuning YOLO, optimizing video processing, and integrating tracking algorithms like DeepSORT, the system can improve detection reliability. Future steps include refining model performance, incorporating additional AI models, and integrating reporting for real-time analytics.